Niteo Blog
Niteo IRL#13 – Lanzarote
Published on 2024/01/24

For the 13th IRL edition, we gathered at our Niteo house in Lanzarote. Nejc had already hosted a few Ocean sprints at the house, so everything ran seamlessly, like a finely-tuned machine. We went through the usual agenda – reviewing the state of the company and projects, planning for the upcoming year, and optimizing internal […]
Read moreEuroPython 2023
Published on 2023/08/08

EuroPython in 2018 was my first international conference. After five years, I eagerly joined another EuroPython. I hopped on a night train and woke up with a view of beautiful sunflower fields near Prague. With the conference starting the next day, I had some spare time to explore the charming city. In the evening I […]
Read moreNiteo Summer IRL meetup in Ljubljana

Our summer In-Real-Life meetup was held in Ljubljana, in the heart of Slovenia. The first things you see as you approach it are castles, numerous parks, and dragons. 🙂 The dragon is the symbol of the city. You will see dragons everywhere… on bridges, at the castle, and decorating railings and buildings. Moreover, Ljubljana is […]
Read moreNiteo IRL#11 – Manila

Mabuhay! It’s winter 2023 and time for our in-real-life meetup. It’s our 11th IRL, but this will be my first time joining one. Because of the COVID lockdowns and the war in Ukraine, I was only able to attend these meetups virtually. We do these IRLs not only for work but also to bond and […]
Read moreFast development on NixOS
Published on 2022/11/10
By Gasper Vozel

We’ve been using NixOS for a few years, and it has proven to be a stable and reliable OS. More importantly, it’s declarative and reproducible, which is one of the main reasons we decided to migrate ~700 of our Ubuntu servers to NixOS. However, it has a few downsides, and one of the biggest ones […]
Read morePyCon JP 2022

It’s good to be back! The past two PyCons in Japan have been online, so it was nice to be back in person where you could actually enjoy the little things in between talks like meeting and talking to other attendees and exhibitors. This year, the event took place in Ariake, Tokyo, which is home […]
Read moreNixCon Paris 2022

After three years, we finally got a proper IRL NixCon. Since the Nix community is not the biggest one, it was nice to talk about Nix for three days (two at the conference and one at the sprint). We heard many interesting talks and answered a few important questions. So let’s start with the most […]
Read moreIndispensable pytest plugins
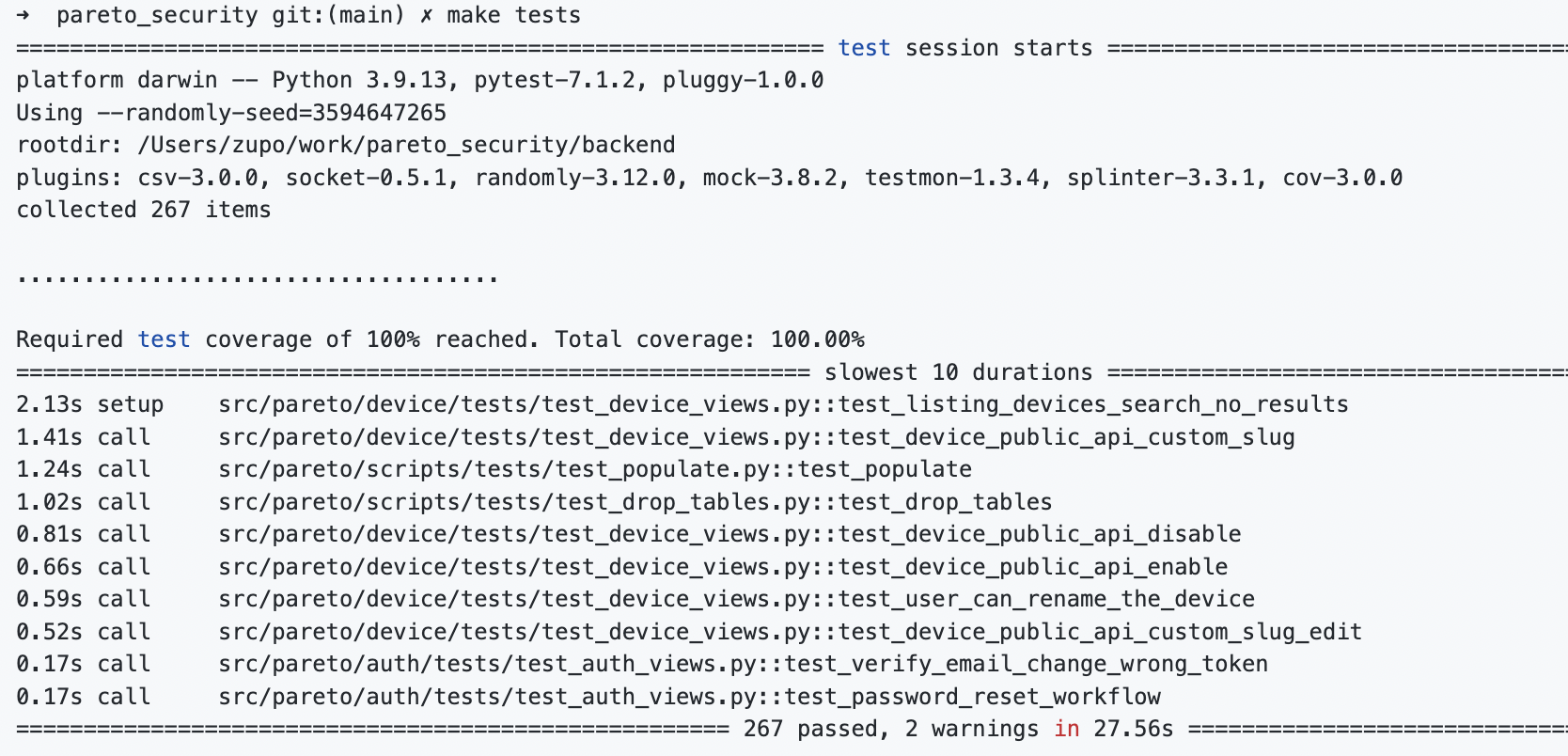
I’ve been babbling on about testing for a decade now. Here’s a quick list of pytest plugins I use in most of my Python projects: pytest-cov – pytest integration for the wonderful coverage tool by Ned Batchelder. pytest-mock – pytest integration for the unittest.mock library. pytest-instafail – Print out the test failure as it […]
Read moreNiteo IRL#10

Man… I can’t believe it has been two and a half years since I was abroad. The last time was actually IRL#8 in Bangkok, Thailand. A global pandemic and Japan’s strict border control sure made it difficult for an expat to go traveling. This time, though, the stars had aligned and I was once again […]
Read morePyCon.IT 2022

At the beginning of the month, I made a quick road trip down to Florence for this year’s edition of PyCon Italia. I try to never miss a chance for a conference I can *drive* to, and Tuscany is just such an awesome place to visit, it really was a no-brainer. The organizers have been […]
Read more